 咨询热线:4008-315-776
咨询热线:4008-315-776
男生学什么技术有钱途? 软件开发师、网络工程师、互联网架构师、WE...
金蛛微信营销 带你实战营销圈 90天实战从零基础到专业大咖
2009年春节期间,中央电视台财经频道《经济半小时》栏目重磅推出春节...
高中生做什么工作好? 标签:汽修、美容、普工、 厨师、文员(No)...
高中生学什么好找工作 学IT,找好工作,就读北大青鸟
我想大声说,站在互联网的风口上,学个好专业,走个好方向,我的青...
北大青鸟东莞金码网络营销学院,是国内知名网络营销培训品牌,汇集行...
东莞金码职业技能培训学校,国家许可办学职业学校!管理严格,推荐...
工欲善其事,必先利其器,第一篇笔记介绍如何搭建源码研读和代码调试的开发环境。 一些必要的开发工具,请自行提前安装:
scala 2.11.8
sbt 0.13.12
maven 3.3.9
git 2.10.2
IntelliJ IDEA 2016.3 (scala plugin)
本人使用macOS 10.12,所有笔记都基于这个系统,但是其他系统也可以很容易找到对应的解决方案,比如IDE的快捷键。
源码获取与编译
从Github上获取Spark源码
可以直接从Spark官方Github仓库拉取。本系列笔记基于 Spark 2.0.2 这个版本,所以先checkout这个tag,再进行之后的步骤:
$ git clone git@github.com:apache/spark.git
$ cd spark
$ git tag
$ git checkout v2.0.2
$ git checkout -b pin-tag-202
如果想要push自己的commits,也可以fork到自己的Github账号下,再拉取到本地,可以参考我之前的文章: Reading Spark Souce Code in IntelliJ IDEA
编译Spark项目
参考官方文档,编译很简单,这里使用4个线程,跳过tests,以此加速编译。这个编译会产生一些必要的源代码,如Catalyst项目下的,所以是必要的一步:
$ build/mvn -T 4 -DskipTests clean package
# 编译完成后,测试一下
$ ./bin/spark-shell
源码导入与代码运行
导入源码到Intellij IDEA 16
现在IDEA对scala支持已经比较完善,导入Spark工程非常简单:
Menu -> File -> Open -> {spark dir}/ pom.xml -> Open as Project
运行实例代码
导入工程后,介绍一下如何运行Spark项目自带的实例代码,在 {spark dir}/examples/ 目录下,这里以 LogQuery 为例:
command + o -> 输入LogQuery打开
1. 配置运行参数:
Menu -> Run -> Edit Configurations -> 选择 + -> Application
参数配置如下:
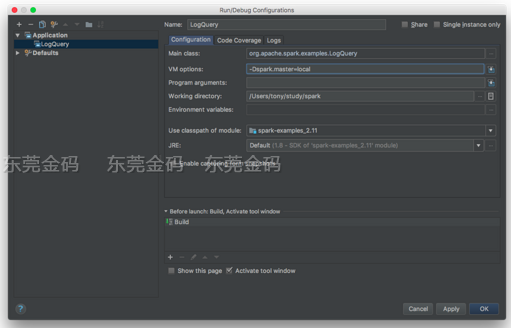
VM options: -Dspark.master=local 代表使用本地模式运行Spark代码,也可以选择其他模式。 保存配置后,可以看到 LogQuery 在运行选项里了:

2. 添加缺失的flume sink源代码
首次运行 LogQuery 会报错,因为IDE找不到flume依赖的部分源码:

解决方案如下:
Menu -> File -> Project Structure -> Modules -> spark-streaming-flume-sink_2.11 -> Sources 1. 把 target目录加入Sources(点击蓝色Sources) 2. 把子目录sink也加入Sources
参考下图,注意右边的Source Folders列表:
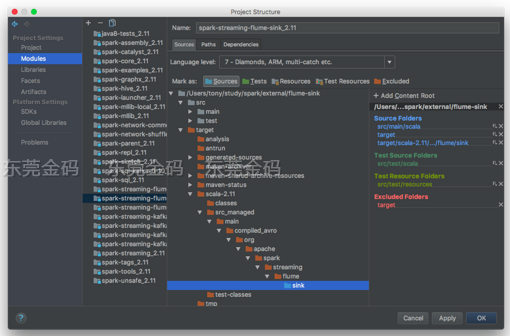
3. 添加运行依赖的jars
再次运行,这次会花费比较长的时间,因为已经可以成功编译 LogQuery 啦,但是还是没能运行成功,报错如下:

不要慌,这说明你的代码编译已经成功啦,运行出错的原因是,运行Spark App一般都是通过 spark-submit 命令,把你的jar运行到已经安装的Spark环境里,也就是所有的Spark依赖都已经有啦,现在你用IDE的方式,就会缺少依赖。
解决方案如下:
Menu -> File -> Project Structure -> Modules -> spark-examples_2.11 -> Dependencies 添加依赖 jars -> {spark dir}/spark/assembly/target/scala-2.11/jars/
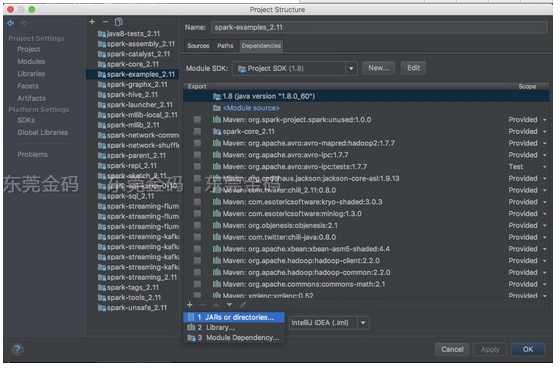
有两点需要注意:
jars/*.jar: 这些依赖jars是在第一步编译打包Spark项目的时候产生的,如果这个目录是空的,或者修改了源代码想更新这些jars,可以用同样的命令再次编译Spark:
$ build/mvn -T 4 -DskipTests clean package
从上图中右侧的Scope一栏可以看到,基本上所有依赖jars都是Provided,也就是说默认都是提供的,因为默认都是用 spark-submit 方式运行Spark App的。
4. 成功运行实例代码
终于再次运行 LogQuery 的时候,可以看到输出啦:
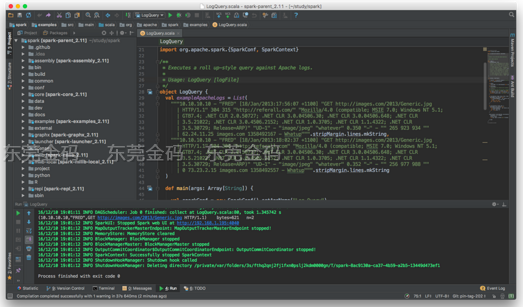
单步调试源代码
千辛万苦地终于让实例代码在IDE里跑起来了,是不是很有成就感。其实做了那么多的铺垫工作,在IDE里面运行代码的最大福利是可以 单步调试 ! 很简单,选择断点,然后 Run -> Debug ,可以看到中间变量值等等,其他的自行探索吧!
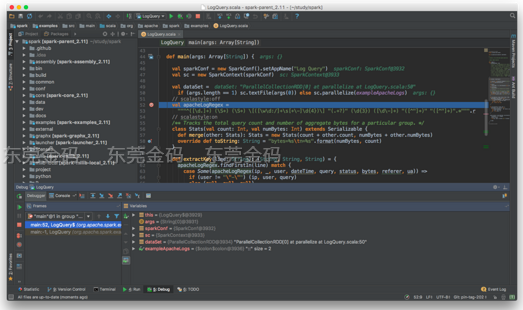

现在这个社会想学电脑的人有很多,因为现在电脑已经和我们的生活息息相关了,也是不可分割的一部分了。是否有很多学生家长就想把孩子送去某一所知名的学校去学电脑呢?那么学电脑到哪里好呢?要说到在哪里学电脑好的话,那要数北大青鸟学校了!

初级程序员程序员软件工程师网络工程师高级网络工程师网络安全与高级应用工程师OSTA软件工程师OSTA网络工程师OSTA Java工程师

2017年1月12日,嘉华教育集团在深圳南山文体中心隆重举办了11周年庆典。出席本次庆典的嘉宾有原外交部副部长胡恩才先生、原深圳大学校长

清晨微风习习,带着初秋的些微凉意。而在东莞市中心的市政广场上,北大青鸟万人晨练签名活动,正火热进行,和以往不同的是,广场上多了一条彩色横幅,“早安青鸟,北大青鸟万人晨练,我们在这里!”这是东莞金码的学员宣言,也是学员们青春正能量的激荡。

北大青鸟东莞金码学校为学生提供住宿条件,干净的楼房,有专人管理打扫,安静环境氛围好,学生可根据意愿选择是否在校住宿。
最近看到很多朋友在前程无忧上抱怨说是工作不好找、企业黄牛、HR不好的帖子。我本身也是个HR,很希望我能给我们公司招到合适的人,因为我不
著名的心理学家马斯洛曾经说过:一个人能够成为什么,他就必须成为什么,他必须忠实于他自己的本性。人需要倾听内在的声音,选择在本质

很多学生求职难,不是因为素质不好、能力不行、经验不够被刷掉,而是因为简历不够闪!找出写简历的突破口、切入点,才能在HR的筛选过程中脱
当你已经面试完了。当你等待公司消息的时候,脑子里不断回放面试的情节,心里估摸着自己的表现如何。但是有什么方法可以在通知出来之前就能
要提高网投简历的成功率,首先要定位好自己,然后定位自己的行业,再定位自己的职位,接下来就是写好自己的简历了:先找一块白板罗列出你所
尽管在过去五年中,社交网络、视频会议和短信带来了巨大的冲击,对于大多数企业通信基础设施而言,电子邮件仍然是杀手级应用。电子邮件
事务是由一组必须要同时完成的或者同时取消的操作组成的,事务通常由高级数据库操纵语言或编程语言(如SQL,C++或Java)书写的用户程序的 执...

营销背景以提升娃哈哈品牌公益内涵为长期目标,配合进行阶段性互动活动为娃哈哈系列新品营销助力。营销创意沿袭社区SNS机理,以娃哈哈年度

前期准备先下载和安装JDK.打开网页之后,选择downloads ,然后选择 Java for your computer.如图1.1所示图1.1所示然后点击下载:如图1....
为存储口令和防止GPU破解程序和类似的资源暴露口令,我们建议结合三种主要技术:采用单向算法、加盐、有意利用慢速算法。

中国新歌声总决赛即将在北京国家体育场上演。在东莞,北大青鸟金码学校第一届金盈好声音校园歌手大赛已经如火如荼地举行。如果说,青春是一

21世纪网络信息时代的来临,日新月异的网络信息技术有力的推动着社会生产力的发展,IT应用触及到每一个角落。IT产业作为国家战略性产业,与

东莞打工者的出路在哪里?相信很多打工者都会问,迷茫,不知道怎么改变,是许多人的通病。东莞是有名的世界工厂,许多打工者在工厂流水
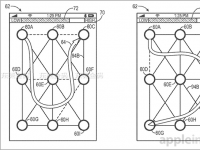
4月18日消息,美国专利与商标局(USPTO)周三公布的一份新文件显示,苹果正在申请两项移动设备手势解锁技术新专利。或许在不久的将来,苹果设

昨天,小编收到了一封信,实际上与其说是一封信,倒不如说是一位父亲的心声。这些情真意切的言辞来自于一位青鸟学员的父亲。我们来看看他都

众所周知,近年来互联网发展飞速,互联网IT技术人才也越来越紧缺,在人才的大缺口下,导致IT技术人才在互联网企业非常抢手,加上IT技术的高

刚从北大青鸟毕业就跳槽转行拿高薪,从2013年以来,我就一直在一家工厂做工,很想跳槽转行,不过因为没有技术特长,没办法找到更好的工

作为东莞唯一的一家北大青鸟中心,东莞金码中心一直倍受瞩目,不仅因其背后北大青鸟的知名度和嘉华教育集团的雄厚背景,也因其在IT技术实战

年终岁末,2017新的一年已经来临,对于没技能没学历的你,是否还在思考自己能做什么工作呢?在21世纪,很多高学历人群都面临着就业困难,对

高考在即,对于平常考试成绩不佳的考生来说,越靠近考试,内心的挣扎与焦虑越多。其中在考试后学什么这个问题上,高考生和家长的担心是最大的,因为成绩这个大关已经难以跨越,内心的疑问就演变成了:高考分数低学什么专业?